
Organizations across the world are striving towards being more data-driven in their decision-making. The right mix of human and machine intelligence is crucial for organizations to succeed in this journey. Machine intelligence needs to be supported with the right data infrastructure, and organizations have invested in setting up the same with the likes of data lakes, data warehouses etc.
At the same time, these investments have not quite provided the outcome that organizations had expected. A common set of challenges that organizations have faced are:
- Business value of insights: Choosing the right use cases and KPIs which could generate valuable insights for the business has always been a challenge.
- Time to insight: While Big Data improved the capability to process data faster, organizations have proceeded to crunch more data. However, the availability of the data in time remains a key aim.
- Cost per insight: Once the data is gathered in the system, a big challenge in making it available for other teams to use is the cost. Big data environments guzzle a lot of computing power which increase the cost of the environment specially in the cloud.
This has led organizations to take a re-look at their data estates and look to address these challenges. Over the years, technologies in the Big Data landscape have continued to change with Spark emerging as the de-facto processing mechanism for data needs. These technologies alleviate the limitations in first-generation big data systems built with Apache Hadoop-based systems with distributions like Cloudera, Hortonworks etc.
In this paper, we highlight how one can approach this modernization path. We have identified Databricks on AWS as the target environment. New generation data platforms are unified i.e. we have the same stack for batch, streaming, machine learning. We have chosen Databricks since it is best performing Spark engine and is the leading player in bringing unified platforms to life
The modernization approach is composed of the following steps
- Separation of Compute and Storage
- Workload Type and Resource Usage
- Data Processing and Data Store Optimization
- Design Consumption Landscape
- Assess Security and Governance
- Data Migration and Movement
Separation of Compute and Storage
One of the founding principles in Hadoop was that for data processing to be scaled horizontally, compute had to be moved to where the storage resided. This would reduce the load on network I/O transfer and make the systems truly distributed. To process the data efficiently, these machines or nodes would have high memory and CPU requirements.
When we transported the same concept to cloud-based environments, the cost of running and scaling started becoming increasingly high. When one is running a data lake, most of the time one needs the storage and not the processing capacity. In Hadoop-based data environments, compute and storage are tied together with HDFS as the file system. E.g. In AWS, d2 is the most cost-efficient storage instance type
In the cloud, object storage is durable, reliable and cheap, while the network capabilities continue to increase. This led to a decoupling of compute and storage, and most cloud-native data architectures are adopting this mode with object storage as the Data Lake. Modern data platforms like Databricks provide the elastic capability required to utilize the power of separating storage and compute.
This has a significant impact on the cost as outlined in the example below taking AWS as an example to store 1PB of data using a 40-node cluster. The calculation was done using the logic that a M5a.8X large cluster will run for about 12 hours a day. This instance type cluster is slightly high, since in most practical cases, due to varied loads, much smaller instance type clusters with fewer nodes can be configured.

Illustrative Cost Comparison (50% utilization)
Assess Workload Type
In addition to separation of storage and compute, data processing time and cost can be optimized through an understanding of the workloads. This impacts both time to insight and cost per insight. In Hadoop-based environments, multiple workloads run on the same cluster to optimize the spend. Hence, it is important to assess the different workloads and their most efficient processing environments. Following is an example of different workloads
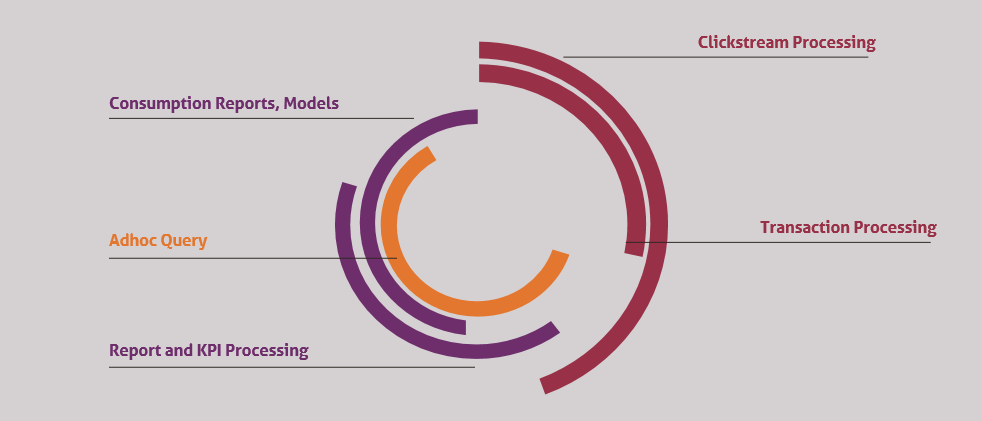
Illustrative Workload Distribution on a 24-Hour Time Scale
- Batch-based data ingestion workloads: These are usually ingested in fixed time intervals. Here too, the workloads are varied.
- Continuous data ingestion in small data streams. Some examples are live transaction data which again could vary between memory and CPU bound processing. However, the required capacity is much lesser.
- Input data like clickstream usually have a lot of JSON which requires memory bound processing.
- Batch processing of typical structured data have more crunching which is usually more CPU bound.
- The real reason behind the data ingestion is to derive insights. Therefore, we have a lot of processing for which we require data aggregation and summary calculations. This has a lot of memory processing.
- Along with this, we have workloads for report calculations, predictive algorithm data processing, ad hoc queries etc.
While one could optimize it at the time of production, over time, the usage patterns change. Data ingestion increases with addition of new data sources. This puts additional pressure on the platform. The increased data processing also requires more time for KPI calculations, leading to contention in resources, in turn also limiting the time and resource available for ad hoc queries. E.g. One Hive query could hog the entire cluster.
As a result, customers experience both under-utilized capacity and a capacity-crunch because of fluctuating demand. It is also not easy to scale up or down on demand due to the specific machine requirements (e.g. EC2 instance types with ephemeral storage as an additional cost). This means that new environments cannot be brought up quickly.
One of the promises of new data technology on the cloud is serverless and on-demand data infrastructure. Separating the workload types and processing times helps us plan for the same. If we look at Databricks, which is designed for running spark effectively in the cloud, we see a built-in cluster manager, which provides features like auto scaling and auto termination. Databricks also provides connectors with cloud storage and integrated notebook environment which helps with development immensely.
Given the power of auto scaling and auto termination, one could design the environment more optimally for the workload types as outlined in the example.
Workload Types and Cluster Configurations
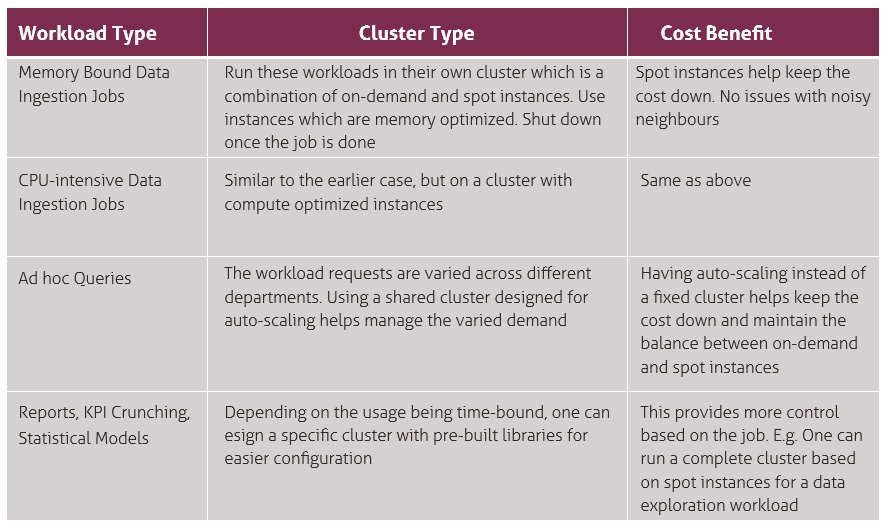
In addition to cost, using the right cluster sizes and types leads to a decrease in processing time. The following example highlights the same.
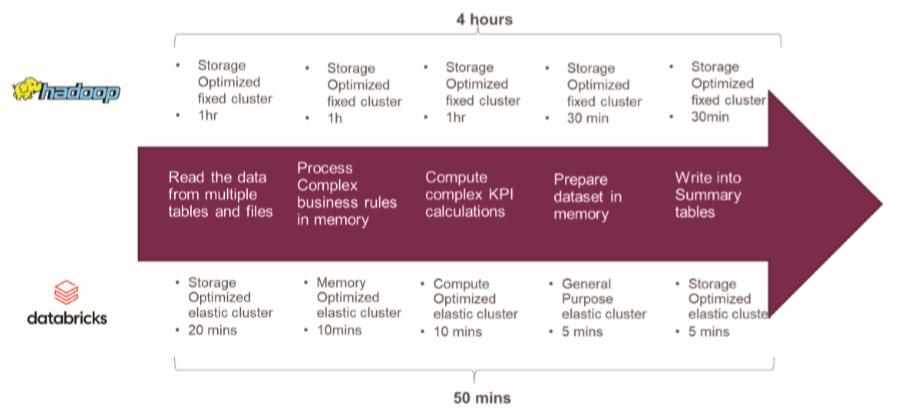
Performance Difference between Data Environments
Download the whitepaper to learn more
